-
[cs224n] 2강 워드 벡터와 워드 센스 (4/5, 글로브와 평가 (GloVe, evaluation))AI 2021. 1. 17. 21:01

여기 우리의 목표함수가 있는데, 약간 더 복잡하게 됐죠. 본질적으로, 우리가 얘기하고 싶은 것은, 여기 제곱된 손실이 있고, 내적은 동시발생 확률의 로그와 가능한 비슷해야 한다는 겁니다. 그것들이 같지 않은 것 만큼의 손실이 있을 겁니다. 그러나 우리는 두 단어 모두에 대해서 바이어스 항을 넣어서, 약간 더 복잡하게 했는데요. 왜냐면 단어는 전체적으로 흔하고 다른 것과 같이 나타날 수 있기 때문이고 혹은 흔하지 않고 나타나지 않을 수도 있죠. 우리는 하나의 트릭을 더 할 건데, 왜냐면 모두 트릭을 써서 성능을 개선하니까요. 앞쪽에 f 함수를 사용해서 우리는 매우 자주 나타나는 단어 쌍이 시스템에 미치는 영향을 제한 (capping)하죠. 이것이 단어 벡터의 글로브 (GloVe) 모델을 제공합니다. 이론적으로 재밌는 건, 앞선 많은 문서들에 이 카운트 방법들과 이 예측 메소드들이 있었죠. 우리가 바라는 것은 이것이 이 둘을 통합해서 보여준 다는 것이죠. 카운트 행렬로 간단히 평가되면서도 같은 종류의 반복적인 손실 기반 추정 방법으로 된다는 거죠. 그 방법들은 좋은 워드 벡터를 얻기 위해 신경망 방법을 위해 사용되었습니다.

이건 좋은 워드 벡터도 줍니다. 여기 개구리에 대한 글로브 결과가 있는데요. frogs와 toad는 명확하죠. 여기 다른 종류의 단어들이 있는데, 다양한 종류의 예쁜 나무 개구리 등등요.

여기서부터 워드 벡터를 평가하는 방법에 대해 얘기하겠습니다. 일반적으로 자연어 처리에서 평가를 하는데 가장 먼저 생각나는건 본질적인 (intrinsic) 대 외적인 (extrinsic) 평가죠. 일반적으로, 우리가 하고 싶은 것이 있으면, 예를 들어 워드 벡터로 워드 유사성을 모델링하거나 아니면 우리는 연설의 일부분을 넣죠. 우리는 얼마나 좋은 일을 했는지에 대해 본질적인 평가를 할 수 있습니다. 스피치의 맞는 부분을 추측하고 있나요? 동의어를 가까이에 놓았나요? 그건 쉽게 할 수 있고, 빨리 계산할 수 있죠. 유용하기도 하죠. 왜냐면 시스템을 이해하게 해주니까요. 한편, 많은 경우에 본질적인 평가는 명확하지가 않습니다. 그것들이 그 작업에 대해서 잘했는지, 혹은 이것이 정말 우리가 매우 열망하는 자연어 이해하는 로봇을 만드는걸 도와주는 지에 대해서요. 사람들은 외적인 평가에도 관심이 많은데, 외적인 평가라는 것은 만약 이 새로운 것을 실제 시스템에서 넣었는데 성능이 올라가지 않는다고 해봅시다. 이건 여러분의 실제 시스템으로서 뭐가 중요한지에 대한 일종의 정의죠. 의미하는 바는 그건 사람이 실제로 관심을 갖고 사용하고 싶어하는 어떤 응용프로그램인데, 예를 들면, 웹서치, 질의응답, 혹은 전화 대화 시스템, 등등이라서 여러분이 시스템에 집어넣으면 숫자가 올라갑니다. 여러분이 원하는 것은 실제 작업에서 동작하는 것들일텐데요. 물론, 한편, 많은 더 어려운 것들이 있죠. 그런 평가를 하려면 훨씬 더 많이 일하고 다양한 시스템에서 실행시켜야 합니다. 결과가 나쁘던 좋던, 가끔 진단하기가 어렵죠. 만약 여러분의 좋은 새로운 워드 벡터가 그 시스템에서 더 잘 동작하지 않는다면, 그건 아마 어떤 외부적 이유겠죠. 여러분의 마법을 가리는 그 시스템이 어떻게 만들어졌냐에 관한 것일 겁니다. 만약 시스템의 다른 부분을 바꾼다면, 갑자기 좋은 결과를 보이기도 합니다. 그래서 좋고 나쁨을 배분하기가 어렵죠.

이 본질적인 워드 벡터 평가에 대해 더 말할건데요. 비유를 연구하는 사람들이 하는 것은 다른 단어 후보 간의 코사인 (cosine) 거리와 각도 연구죠. 어떤 것이 비유를 풀 단어인지를 연구하는 거죠. 어떤것이 차이의 작은 주름인지를요. 사람들이 자주 쓰는 트릭은 시스템이 비유에 집어넣은 단어 3개 중 하나를 반환하지 못하게 하는거죠.
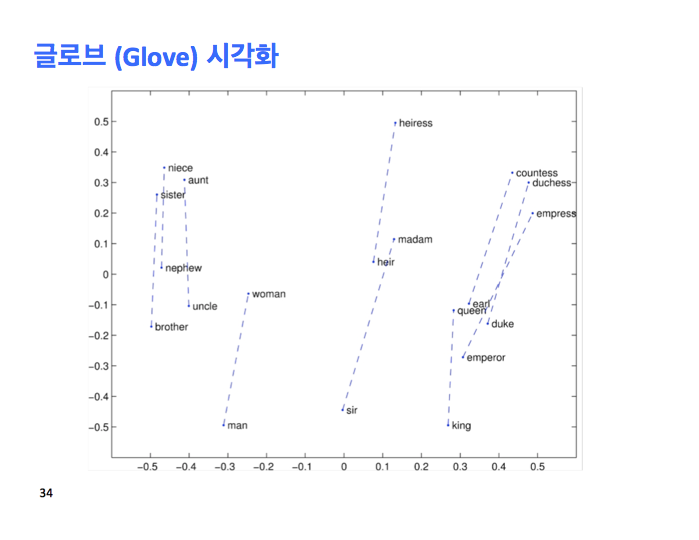
이게 여러분이 평가할 수 있는 거죠. 여기 글로브 시각화한 것이 있는데, 더그 로디가 발견한 선형 특징과 똑같은 종류의 것을 보여주죠. 즉, 컨스트럭션 (construction)에 의해서 비유가 동작한다는 겁니다. 왜냐면 우리의 벡터 공간은 의미 컴포넌트를 선형으로 만들고 싶거든요. 이건 젠더 (gender) 디스플레이입니다.
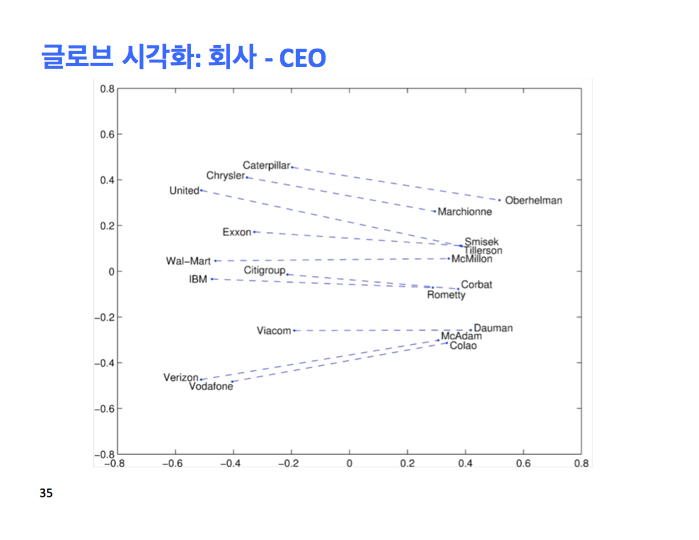
이건 회사와 CEO 관계를 보여주죠.
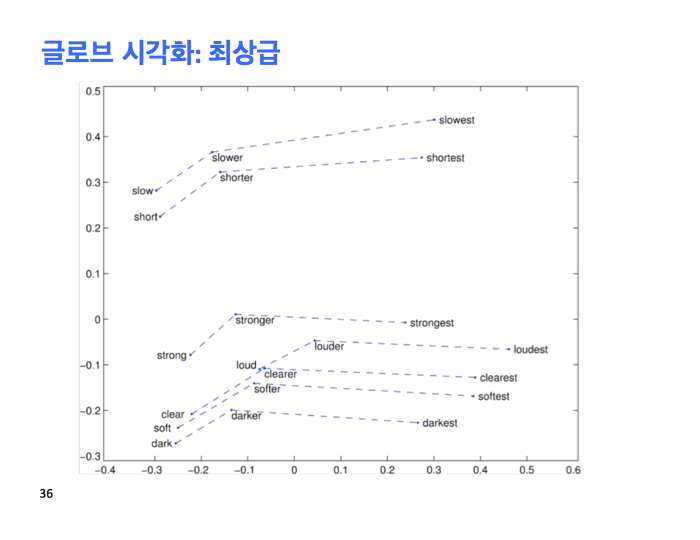
이건 구문적 사실도 보여줍니다. 형용사의 긍정 비교와 최상급을 보여주죠.

토마스 미콜로브가 이 비유 작업에 대한 아이디어를 냈고 비유를 많이 넣은 데이타 셋을 만들었죠. 좀 이상한 데이타 셋인데, 임의의 다른 것들을 테스트해서 그의 시스템에서 잘 동작했습니다. 그건 나라와 수도를 테스트하고 나라 도시 주, 나라와 화폐 등요. 많은 의미적인 것들을 테스트했습니다

구문적인 것들은 형용사 비교, 최상급 등이 있습니다. 앞서 보여준 것들도 있지만, 거기엔 오바마 - 클린턴과 같은 것들은 이 시스템에 없죠.,

이건 큰 결과 테이블인데, GloVe 논문에 나옵니다. 놀랍지 않게 글로브 논문은 이 평가에 가장 잘 동작합니다. 왜냐면 우리 논문이니까요. 아마도 눈치를 채기 시작할텐데, 만약 카운트에 대한 단순한 SVD를 한다면, 이 비유 작업에서 그건 지독하게 나쁠겁니다. 더그 로디가 보여준 것은 만약 SVD 전에 카운트 행렬을 조작한다면, 그럼 이 작업에 잘 동작하는 SVD에 기반한 시스템을 만들 수 있다는 것이죠. 다른 것들에도 나쁘지 않구요.
또 발견할 수 있는건, 제일 위에 100차원이 있는데, 아래엔 1000차원이 있고, 300차원도 있구요. 적어도 많은 양의 텍스트를 학습시킬 땐, 더 큰 차원이 더 잘 동작합니다. 텍스트의 양이 차이를 만들죠? 처음엔 10억에서 15억 단어로 올라가고, 아래엔 420억 단어를 학습시키죠. 놀랍지 않게, 420억 단어가 더 잘 동작하죠. 빅데이타입니다.

여기 논문의 몇 단계가 더 있죠 . 이건 차원의 그래프와 성능이 어떤지를 보여주죠. 3개의 초록색은 의미적이고, 파란색은 구문적 비유이고, 빨간색은 전체적인 점수죠. 여기서 볼 수 있는 것은 300 차원까지 명확하게 증가하지만 그 다음 꽤 평평해 집니다. 정확하게 왜 여러분이 300차원의 벡터를 많이 찾는 지에 대한 이유죠. 두번째 것은 윈도우 크기를 보여주는데, 이건 일종의 대칭성에 대해 얘기했던 거죠. 양쪽 윈도우 크기는 2, 4, 6, 8, 10으로 올라갑니다. 볼 수 있는건 작은 윈도우 2를 쓰면, 동작하기는 하지만, 구문적 예측이 강하죠. 구문적 효과는 그지점에 관련되어 있기 때문입니다. 의미적 예측이 점점 더 좋아지죠. 구문적도 좋아지지만요. 오른쪽은 한쪽만 문맥을 사용한 것인데, 숫자가 좋지 않죠. 까메오로 최근 연구에 대해서 약간 들어가보죠. 사람들이 워드 벡터로 먼저 뭘하고 있는지에 대해서요.

두 명의 스탠포드 사람들인데, 진 인과 유아유안은 사실 영리하고 매우 수학적 아이디어를 내서 여기서 그들은 행렬 섭동 (perturbation) 이론을 썼죠. 보여주는건 워드 벡터의 차원은 바이어스 베리언트 트레이드오프 (bias variant trade-off)로 입력이 되는거죠. 이 논문을 쓰고 유럽에 발표하러 갔죠. 이 워드 벡터에 대한 재밌는 결과가 있는데, 놀라운점은 워드 벡터 차원을 0부터 우리가 얘기한 것보다 훨씬 높게 1만까지 올렸습니다. 발견한 점은 사람들이 수년동안 알던 것은, 2-300근처에 성능을 최적화하는데 작은 일시적 문제가 있다는 겁니다. 그래서 그 크기를 썼죠. 그것이 그들의 이론의 대부분인데, 놀라운 건, 만약 엄청나게 많은 숫자가 있다면, 예를 들어 1만 차원 벡터를 쓴다면, 모든 단어에 대해 2의 제곱의 크기로 추정을 하는 겁니다. 반드시 실패할 겁니다. 왜냐면 학습 데이타에 비례해서 절망적으로 많은 파라미터가 있을 테니까요. 그 데이타로부터 이 숫자들을 추정해야 하죠. 재밌는 결과는 실패하지 않은 건데, 그래서 이 엄청난 차원으로 갈 수 있는데, 성능은 플랫해 지죠. 왜 그들이 거기까지 갈 수 있었는 지에 대해 예상하는 것에 대한 많은 이론이 있습니다.

이 모델을 반복적으로 학습시키면, 오렌지 색은 글로브 트레이닝인데, 한동안 계속 좋아지다가, 24시간 동안 하면 초기 6시간동안 한 것보다 낫죠. 유감스럽게도 그건 많은 딥러닝 모델에서 사실입니다.

몇가지 더 있는데 의미적, 구문적 그리고 전체 숫자인데요. 여기 2가지가 섞였는데, 하나는 오버롤 숫자를 보면, 제일 높은 게 여기 있고, 420억 커먼 크롤 웹페이지 코퍼스요. 그게 최고 점수를 주네요. 다른 재밌는건 위키피디아로 한 건 잘 동작한 다는 거죠. 16억 위키피디아 토큰이 43억 뉴스와이어 기사 데이타 토큰보다 더 잘 동작하죠. 이게 말이 되는 이유는 백과사전의 일이 사물이 서로 어떻게 관계됐는지 컨셉을 설명하는 것이기 때문이죠. 백과사전은 사물들간의 관계를 보여주는 훨씬 더 설명적인 텍스트죠. 반면 신문기사는 어떻게 사물들이 서로 들어맞는 지 보여주진 않죠. 그들은 그냥 말하죠. 누가 어제 총 맞아 죽었는지 등등에 대해서요 . 이건 재밌는 사실인데 위키피디아 데이타가 진짜 워드 백터 만들때 유용하다는 거죠. 사실 우리가 글로브 워드 벡터 없이 잘 했을 때, 많은 사람들이 그걸 썼는데, 그게 잘 동작하는 이유중 하나는 구글이 배포한 오리지널 (original) 워드2벡 벡터가 구글 뉴스 데이타로 만들었기 때문인 것 같아요. 다른 곳에서는 위키피디아 데이타를 사용했죠.
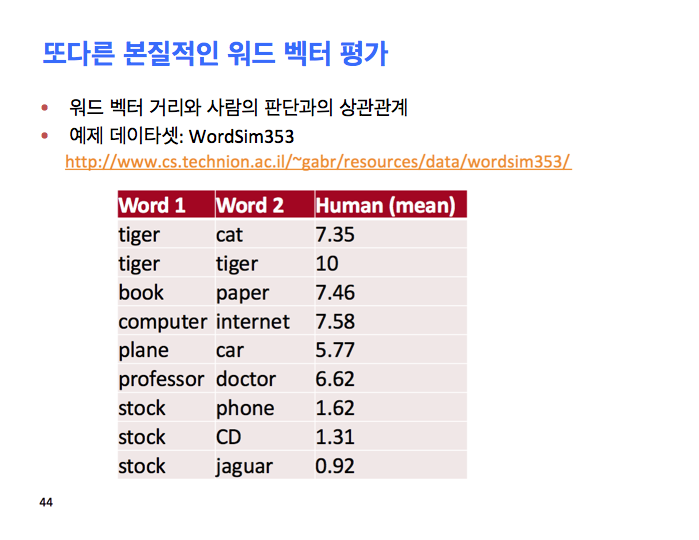
그게 비유에 대한 모든 작업이죠. 다른 더 기본적인 평가는 이 유사성을 잡아내는 판단이죠. 이것에 대해 많이 얘기하지 않았는데, 이건 심리학 커뮤니티의 큰 서브 리터러쳐 (sub literature)인데, 거기선 사람들이 사람의 유사성 판단을 모델링하고 싶어했죠. 좋은 심리학 사람처럼 여러분이 하는 건, 심리1 과목의 학부 교실을 찾아서, 쌍으로 된 단어를 보여주고 이것들의 유사성에 대해 1- 10점 스케일로 점수 매기도록 하는거죠. 많은 데이타가 모아졌고, 사람의 평균에 대해 작업하면 이런 점수가 나오죠. 고양이 호랑이 7.35, 호랑이 호랑이 10, 등등요. 그 다음 말하고 싶은건 우린 이 공간의 거리를 이 유사성 판단에 매핑하고 싶은겁니다. 얼마나 잘 될까요?
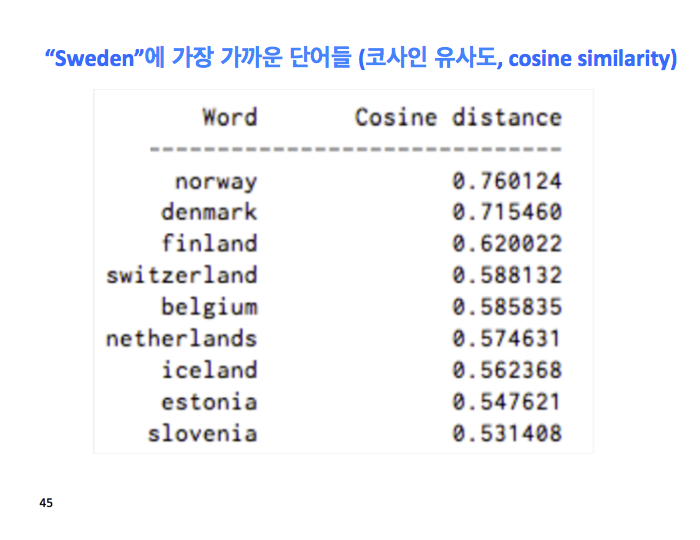
그건 일종의 유사성 판단인데요.

그리고 이 시스템을 위해 사용됩니다. 다시, 여기 많은 모델이 있는데 이건 글로브 논문에서 가져왔습니다. 여기 유사성 데이타셋이 있죠. 가장 잘 알려진건 워드심 353으로, 그 속에는 353개의 다른 것들이 있는데, 그래서 여러분은 여러분의 유사성 판단과 사람들로부터 온 것과의 상관관계를 가지고 일종의 모델링을 하죠.
'AI' 카테고리의 다른 글
[cs224n] 5강 의존성 파싱 (1/4, 구문 구조 (phrase structure)) (0) 2021.01.26 [cs224n] 2강 워드 벡터와 워드 센스 (5/5, 워드 센스 (Word Senses)) (0) 2021.01.18 [cs224n] 2강 워드 벡터와 워드 센스 (3/5, 동시발생 (co-occurrence count)) (0) 2021.01.17 [cs224n] 2강 워드 벡터와 워드 센스 (2/5, 최적화 (optimization)) (0) 2021.01.17 [cs224n] 2강 워드 벡터와 워드 센스 (1/5, 워드 벡터와 워드2벡 (word vector, word2vec)) (0) 2021.01.16