-
[cs224n] 5강 의존성 파싱 (4/4, 신경 의존성 파싱 (neural dependency parsing))AI 2021. 1. 27. 19:36

이제 설명하고 싶은건 신경 의존성 파서입니다 . 왜 그것들이 동기부여가 되었는지도요. 이전의 모델은 이런 지시자 피쳐 (indicative features)가 있는데, 스택의 탑은 'good'이라는 단어고, 두번째 단어는 동사 'has'였죠. 스택의 탑의 단어는 어떤 다른 단어고 탑의 두번째는 그 문장의 다른 부분이고, 그 부분은 이미 다른 부분의 의존성으로 연결되었구요. 사람들은 이 피쳐들을 핸드 엔지니어 (hand engineer)했죠. 거기서 문제는, 이 피처들이 매우 성기다 (sparse)는 겁니다. 이 피쳐들이 매칭되는 게 매우 적어요. 그들은 몇몇 구성들과 매칭되지만 다른 피처들은 불완전하기 마련이죠. 그들은 흔히 수 백만개의 피쳐들입니다. 스택과 버퍼에 어떤 구성을 갖기 위해서는 이 피쳐들을 계산하는 것은 그냥 비싸기만 합니다. 그 다음 이 피쳐들 중 어떤 것이 스택과 버퍼 구성에 대해 액티브한지 알고 싶습니다. 그래서 피쳐의 포맷에 대해 계산해야 합니다. 기존의 의존성 파서는 이 피쳐를 계산하는데 시간을 거의 다 쓴다고 알려졌죠. 이후 쉬프팅, 리듀싱, 혹은 순수한 파싱 연산을 하기 보다는 머신러닝 모델로 갔구요. 그건 가능성을 열어준 것 같은데요. 이 왼쪽 아래 규칙들을 없애면 어떨까요? 그리고 신경망을 스택과 버퍼 구성에 직접 돌리는 겁니다. 그럼 아마 우리는 기존 파서보다 더 빠르고 성김 (sparsity) 이슈가 덜한 의존성 파서를 만들 수 있죠.

그게 2014년의 단 치 첸과 저의 프로젝트였죠. 우리는 신경 의존성 파서를 만들었습니다. 사실 우리가 발견한 건 그게 실제 가능한 일이라는 겁니다. 여기 몇 개의 통계가 있는데, 이게 UAS와 LAS죠. 말트파서 (MaltPasrser)는 앞서서 봤던 요야킴 니브레의 파서구요. 그들은 89.8 UAS를 얻었죠. 모두 좋아했습니다. 이유는 469 문장을 1초에 파싱했거든요. 더 복잡한 방식으로 파싱을 한 다른 사람들도 있었는데, 그건 그래프 기반 의존성 파서였죠. 이게 90년대의 또다른 유명한 의존성 파서죠. 좀 더 정확하지만 2차의 크기로 더 느린 비용이 들죠. 사람들은 그 기반 위에 더 연구해서 2000년대 부터 훨씬 더 복잡한 그래프 기반 파서를 만들었습니다. 약간 더 정확하지만 더 느려졌죠. 우리가 보여줄 수 있었던 건 요야킴 니브레 스타일의 쉬프트-리듀스 파서의 결정을 하는 신경망을 사용하는 대신, 우리는 그 당시 가용한 거의 최고의 것 만큼 정확한 것을 만들 수 있었다는 것이죠. 우리는 엄밀히 LAS에선 이겼고 UAS엔 살짝 뒤졌죠. 그건 니프레의 파서 만큼 빠를 뿐 아니라, 사실 더 빨랐죠. 왜냐면 우린 피쳐 계산에 그만큼 시간을 쓰지 않았거든요. 그게 사실 거의 놀라운 결과죠. 우리가 아무것도 하지 않아도 됐다는 건 아닙니다. 우리는 신경망에서 매트릭스 곱하기를 해야 했죠. 결국 그가 했던 피처 계산보다 행렬 곱하기를 더 빨리 할 수 있었죠. 비록 결국 그건 가중치를 보고 서포트 벡터 머신으로 가는 것이긴 했지만요.

단어에 대해서 봤듯이 비밀은 분산된 표현을 이용하는 것이었습니다. 그래서 이미 봤듯이 각각의 단어에 대해 그걸 워드 임베딩으로 표현하는 것입니다. 특히, 워드 벡터를 이용할 건데, 그걸 사용해서 우리의 파서에서 단어의 표현으로 사용할 겁니다. 그러나 만약 분산 표현에 관심이 있다면, 아마도 단어에 대한 분산 표현만 가져야 할 것 같네요. 어쩌면 다른 것에 대한 분산 표현을 가지는 것도 좋지만요. 우리는 명사, 동사, 형용사 등등 문장의 일부가 있는데, 어떤 부분들은 다른 것들보다 훨씬 서로 많이 관련되어 있죠. 특히, 대부분의 자연어 처리 연구는 잘게 쪼개진 부분을 사용합니다. 명사, 동사 같은 부분만 있는 게 아닙니다. 여러분은 단수 명사 대. 복수명사도 있고 다른 부분들도 있죠. 문장의 어디에 있느냐에 따라서 work, works, working 같은 다른 형태도 있죠. 그렇게 클러스터를 이루는 문장 부분 레이블의 집합이 있습니다. 어쩌면 우리는 그들의 유사성을 표현하는 부분의 분산된 표현을 가질 수 있죠. 만약 우리가 그걸 한다면, 왜 계속 의존성 레이블을 계속하지 않을까요? 그들도 분산 표현을 가지는데요.

우리는 그것을 하는 표현을 만들었습니다. 아이디어는 우리의 스택에 스택의 탑의 포지션과 버퍼의 첫 포지션을 가지고, 각각의 포지션에 대해 단어와 문장의 일부를 가지고 있습니다. 만약 우리가 구조를 여기처럼 만들었다면, 우리는 이미 만들어진 의존성에 대해 알 수 있습니다. 그래서 우리는 각각의 포지션에 대한 트리플 (triple)을 갖게 되고 그 모든 것을 분산 표현으로 바꿉니다. 그걸 우리가 학습하고 그 분산 표현을 사용해서 파서를 만듭니다. 다음 강의부터 신경 모델의 더 복잡한 형태를 사용할 겁니다. 그러나 이 모델은, 매우 간단하고 직관적인 방식인데, 우리는 그냥 쉬프트와 왼쪽 아크와 오른쪽 아크를 하는 니브르가 사용했던 파서와 똑같은 모델을 사용할 수도 있습니다. 우리가 신경망으로 변경하는 유일한 부분은 신경망으로 통제해서 다음에 뭘 할 지를 결정하는 겁니다.
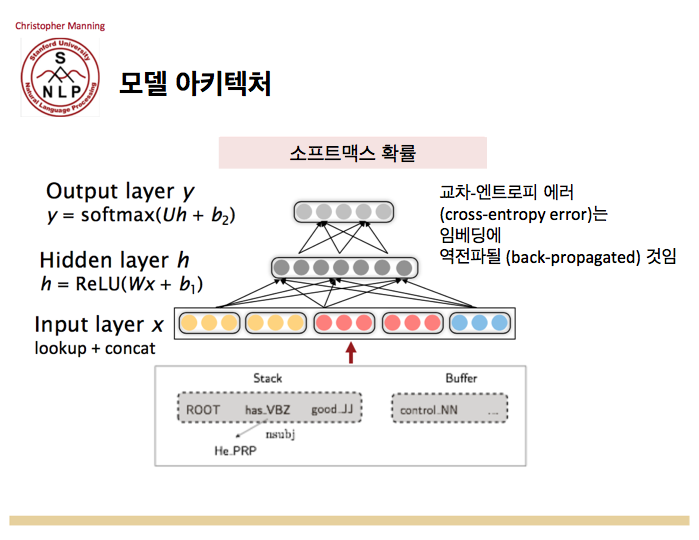
우리의 신경망은 지난주에 얘기했던 종류의 매우 간단한 분류기인데요. 구성에 기반해서, 우리는 입력 레이어를 만들고 (앞슬라이드 오른쪽 3열) 이 박스들을 받아들여서 각각의 단어들에 대한 벡터 표현을 찾습니다. 그리고 그것들을 합쳐서 입력 표현을 만듭니다. 윈도우 분류기를 만들 때와 유사하죠. 우리는 많은 것들을 함께 연결할 수 있습니다. 그것을 입력 레이어에 넣습니다 . 그 다음 우리는 지난주처럼 히든 레이어를 거치게 하고, 우리는 Wx + b를 하고 히든레이어에 대해 렐루 (ReLU)나 비선형을 거치게 합니다. 그 위엔 간단히 소프트맥스 (softmax) 출력 레이어를 붙입니다. 다른 행렬을 곱하고 다른 바이어스 항을 더해서, 그걸 소프트맥스로 넣으면 우리의 액션에 대한 확률이 나오죠. 쉬프트인지 왼쪽 아크인지 오른쪽 아크인지 혹은 해당하는 것을 레이블과 함께 액션에 대한 확률이 나옵니다. 그 다음 우리는 같은 종류의 크로스 엔트로피 (cross entropy) 손실을 사용해서 문장의 트리뱅크 파싱에 따라 우리가 취해야 할 액션을 추측하는데 있어서 얼마나 일을 잘 했는지 얘기하는거죠. 쉬프트 리듀스 파서의 각 스텝마다 우리는 다음에 뭘 할지 결정합니다. 우린 그걸 이 분류기로 하고 올바른 액션에 대해 확률로 1을 주지 않을 정도로의 손실을 얻습니다. 그게 트리뱅크를 사용해 우리가 이룬 것이죠.

우리는 파서를 훈련시켜서 문장을 예측할 수 있게 됐습니다. 멋진 것은 이게 니브르의 파서의 좋은 것들을 다 가지고 있는데, 그것이 밀도높은 표현을 사용하게 함으로써 우리는 니브르의 파서보다 더 좋은 정확도와 속도를 동시에 얻었죠.
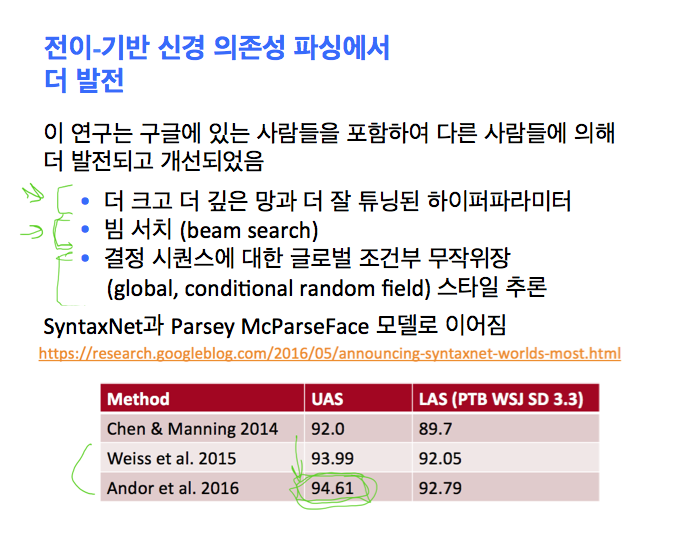
여기 그 결과가 있습니다. 기본적으로 우리의 파서가 이전 것보다 성능이 뛰어나다는 겁니다. 우리가 이 연구를 한 이후에, 구글 사람들인 와이스 (Weiss)와 안도 (Andor)의 논문들에서 "이게 멋지다고 했고, 우리 신경망을 더 크고 더 깊게만들고 시간을 많이 들여서 하이퍼파라미터를 튜닝하면, 숫자들 더 좋게 할 수 있다"고 말했죠. 슬프지만 사실이죠. 신경망을 만들 때 이 모든 것들이 도움이 됩니다. 그들은 이미 얘기했던 빔 서치 (beam search)에 넣었습니다. 빔 서치는 진짜 도움이 될 수 있죠. 빔 서치에서 '다음 액션이 뭔지 알아보자 그걸하고 반복하자'라고 말하는 대신에, 말하면서 여러분은 스스로 서치를 해보는 겁니다. 예를 들면, "2 액션을 살펴보고 어떻게 되는지 보자"라고 하는 거죠.
질문: 이 트리 어떻게 만들지에 대해 사람들이 동의하나요?
답: 사람들은 항상 동의하진 않습니다. 기본적으로 동의할 수 없는 2 가지 이유가 있죠. 하나는 사람은 엉망이죠. 이걸 하는 사람의 연구가 완벽하지 않습니다. 다른 건 그들을 일반적으로 다른 구조가 있을 거라고 생각합니다. 그건 상황에 따라 다릅니다. 만약 사람에게 문장을 파싱하라고 하면, "뭐가 합의고 뭘 생산할까요?" 아마도 여러분은 92%인 뭔가를 얻을 겁니다. 그러나 만약 결정을 하기 위한 말을 하면, 다시 말해서 "이 차이를 봐요 이게 맞을까요? 틀릴까요?"라고 하면 , 사람들 중 한명은 사실 "네 제가 실수했어요."라고 하죠. "신경쓰지 않았네요." 등등의 말도 하죠. 사람들이 가능한 파싱에 대해 사실 동의하지 않는 오차율은 얼마일까요? 아마 3% 이상 정도일 거에요.
하지만 그런 경우들이 있죠. 거기엔 전치사 부가 모호성도 포함됩니다. 때로는 여러개의 추가적인 부가가 있는 경우도 있어서, 뭐가 맞는지 명확하지 않는 경우가 있죠. 뭐가 틀렸는지 명확한 경우도 많이 있지만요. 더 잘 할 여지가 있죠. 언레이블드 어태치먼트 점수에서 매우 좋게 시작했습니다. 더 잘 할 수 있습니다. 빔 서치에서 그들이 마지막으로 한 건 여기서 말 안하겠지만, 전체적인 추론인데, 그게 지각력이 있다는 것을 확실히 하는 거죠. 그게 구글이 이 모델을 만들도록 했죠. 거기에 멍청한 이름을 붙였는데 Parsey McParseFace 파싱 모델이라구요. 그게 숫자를 훨씬 더 위로 올렸죠. 언레이블드 정확도 점수는 95% 가까이 됐습니다. 딥 러닝 사람들은 최적화를 좋아하죠. 그 사이 2년동안 이 연구를 계속해서 다시 점수가 높아졌죠. 이게 더 나은 파서의 시대로 이끌었습니다. 매우 효과적인 90년대의 파서는 90퍼센트 정도였는데, 이건 새로운 신경 트랜지션 기반 의존성 파서 세대로 들어선거죠. 우리는 에러율을 반으로 줄여서 지금은 5% 에러율이죠. 스탠포드가 포함된 더 연구한 결과가 있습니다. 다른 학생인 팀 토사는 최근 연구에서 95%보다 더 좋은 결과를 냈죠.
'AI' 카테고리의 다른 글
[cs231n] 4강 역전파와 신경망 (2/4, 역전파 심화, advanced backpropagation) (0) 2021.02.05 [cs231n] 4강 역전파와 신경망 (1/4, 역전파, backpropagation) (0) 2021.02.05 [cs224n] 5강 의존성 파싱 (3/4, 전이 기반 파싱 (transition-based parsing)) (0) 2021.01.27 [cs224n] 5강 의존성 파싱 (2/4, 의존성 문법과 구조 (dependency grammar and structure)) (0) 2021.01.27 [cs224n] 5강 의존성 파싱 (1/4, 구문 구조 (phrase structure)) (0) 2021.01.26