-
[cs231n] 11강 탐지와 분리 (Detection and Segmentation) (2/4, 분류 + 위치찾기 (classification + localization))AI 2021. 4. 26. 17:39

다음 작업으로 얘기하고 싶은 것은 이 분류 더하기 위치 찾기 (classification plus localization)아이디어입니다. 이미지 분류에 대해서 많이 얘기했는데, 여기서 우리는 그냥 입력 이미지에 어떤 카테고리 레이블 (category label)을 붙이고 싶었죠. 그러나 가끔 여러분은 이미지에 대해서 좀 더 알고 싶을 수도 있죠. 카테고리가 뭔지 예측하는 것 뿐만 아니라, 이 고양이의 경우에서, 여러분은 이미지에서 그 객체가 어디 있는지 알고 싶을 겁니다. 고양이 카테고리 레이블을 예측하는 것 뿐 아니라, 그 이미지에서 고양이 영역 주변에 경계 상자 (bounding box)를 그리고 싶을 수도 있죠. 분류 더하기 위치 찾기를 여기서 객체 탐지 (object detection)와 구별하는 것은 위치 찾기 시나리오에서는 여러분은 미리 이미지에서 찾고자 하는 객체가 정확히 하나가 있다는 것을 알고 있다고 가정하는 거죠. 혹은 어쩌면 하나 이상일 수도 있죠. 그러나 미리 이 이미지에 대해서 어떤 분류 결정을 해야 한다는 것을 알고 있는 겁니다. 그리고 우리는 정확히 하나의 경계 상자를 만들어 낼 겁니다. 그 객체가 이미지 내에서 어디 위치하고 있는지를 알려주는 상자죠. 그래서 가끔 그 작업을 분류 더하기 위치 찾기라고 부릅니다.

우리는 이 문제와 씨름하기 위해서 이미지 분류로부터 배운 것과 같은 시스템을 많이 재사용할 수 있습니다. 이 문제를 위한 기본적인 아키텍처 (architecture)는 이것 처럼 보일 겁니다. 우리는 입력 이미지를 어떤 거대한 합성곱 망으로 넣죠. 이건 알렉스넷 (AlexNet)입니다. 알렉스넷은 어떤 최종 벡터 (vector)를 제공하는데, 그건 이미지의 내용을 요약해 줍니다. 그리고 나면 이전처럼 우리는 최종 벡터로부터 클래스 점수로 가는 어떤 완전 연결 계층을 가질 겁니다. 그러나 이제 우리는 벡터로부터 4개의 숫자로 가는 또다른 완전 연결 계층을 가질 건데, 그 4개의 숫자는 경계 상자의 높이, 넓이, 그리고 x, y 위치 같은 거죠. 우리의 망은 이제 이 2개의 다른 출력을 만들어 냅니다. 하나는, 클래스 점수 집합이고, 다른 하나는 입력 이미지내의 경계 상자의 좌표를 알려주는 이 4개의 숫자죠.
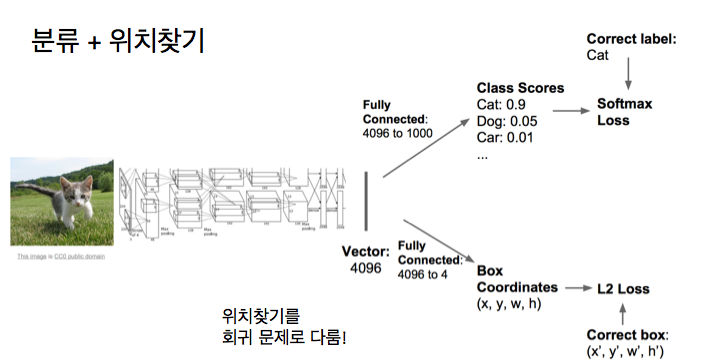
이 망을 훈련시킬때, 우린느 사실 두개의 손실을 가질 겁니다. 이 시나리오에서는, 우리는 일종의 완전 지도학습 설정 (fully supervised setting)을 가정하고 있는 거죠. 우리는 훈련 이미지 각각이 카테고리 레이블이 달려있고, 이미지 내의 그 카테고리에 대한 정답 경계 상자 (ground truth bounding box)가 있다는 것을 가정하는 거죠. 이제 2개의 손실 함수가 있습니다. 우리는 정답 카테고리 레이블과 예측된 클래스 점수를 사용해서 계산하는 가장 자주 사용하는 소프트맥스 (softmax) 손실이 있죠. 그리고 또한 경계 상자에 대한 예측된 좌표와 경계 상자에 대한 실제 좌표간의 차이를 측정하게 해주는 어떤 종류의 손실이 있습니다. 매우 단순한 한가지는 그 둘 간의 L2 손실을 하는 거죠. 그게 실제에서 보게 될 가장 간단한 것일 겁니다. 비록 사람들은 가끔 이것에 대해 이것저것 해보지만요. 아마 L1이나 smooth L1을 사용하거나 경계 상자를 약간 다르게 파라미터화하지만, 아이디어는 항상 같습니다.

예측된 경계 상자 좌표와 정답 경계 상사 좌표 사이에는 어떤 회귀 손실이 있다는 거죠.

그리고 제가 언급했듯이, 이 큰 망은 이미지넷 같은 것으로부터 가져와서 사전학습된 망입니다.

여담으로 잠깐 얘기하면, 이미지내에서 고정된 숫자의 위치를 예측하는 이 아이디어는 단지 분류 더하기 위치찾기에만 적용되는 것이 아니라 많은 다른 문제들에도 적용될 수 있습니다. 하나의 멋진 예가 사람 자세 추정이죠. 여기서 우리는 사람 이미지를 받고 싶은 거고. 그 사람의 관절 위치를 출려하고 싶은 겁니다. 이것으로 사실 망은 그 사람의 자세가 어떤지 예측할 수 있습니다. 그 사람의 팔이 어디있고, 다리가 어디있는지 등 같은 거죠. 일반적으로 대부분의 사람들은 같은 숫자의 관절을 가지고 있죠. 그것은 단순화하는 가정이죠. 그게 항상 사실이 아닐 수도 있지마나 망에 대해서는 동작합니다. 예를 들어 어떤 데이타셋에서 볼 수 있는 하나의 파라미터화는 사람의 자세를 14개의 관절 위치로 정의하는 겁니다. 그들의 발, 무릎, 엉덩이 같은 것 말이죠.

이제 망을 훈련시킬 때, 사람 이미지를 입력할 거고 이 경우 14개 관절 각각에 대한 x, y 좌표를 출력하는 거죠. 그리고나서 어떤 회귀 손실을 저 14개의 예측된 점수에 적용하고 그냥 이 망을 역전파로 다시 훈련시키는 거죠.

L2 손실을 해볼 수도 있지만 사람들은 다른 손실들도 여기에 해볼 수 있는 거죠.
'AI' 카테고리의 다른 글