-
[cs231n] 1강 시각 인식을 위한 합성곱 소개 (3/3, 강좌개요)AI 2021. 1. 1. 18:07


이 강좌는 이미지 분류 (image classification)에 초점을 맞춥니다.이미지넷 챌린지에서 좀 봤었죠. 알고리즘이 이미지를 보고 정해진 카테고리로 그 이미지를 분류하는 겁니다.

제한적이고 인공적인 셋업인 것 같지만, 꽤 일반적입니다. 다른 여러 세팅에서도 사용할 수 있습니다. 산업과 연구 등등에서요. 음식이나, 음식의 칼로리를 인식한다거나 예술 작품이나 제품을 인식할 수도 있고, 이미지 분류의 기본 도구가 굉장히 유용하고 많은 어플리케이션으로 사용될 수 있습니다.

다른 시각 인식 문제도 얘기할 건데요. 이미지 분류를 위해 만든 도구들 위에 만든 다른 시각 인식 문제들도 얘기할 겁니다. 바로, 물체 탐지와 이미지 캡셔닝입니다.
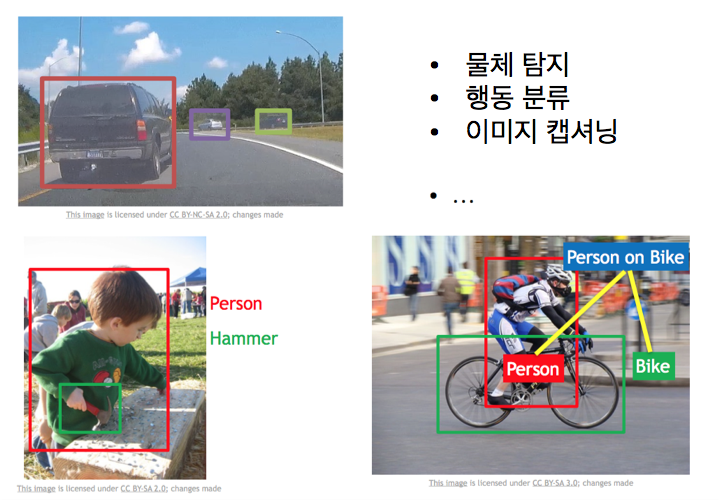
물체 탐지에서의 세팅은 좀 다릅니다. 개, 고양이 같은 것으로 이미지를 분류하는 것이 아니라 이미지 내에서 말이 여기, 고양이가 여기 있다고 네모를 그리는 겁니다. 이미지 캡셔닝은 이미지가 주어지면 이미지를 설명하는 자연어를 생성하는 것인데, 어려워보이지만 이미지 분류를 위한 도구들이 재사용됩니다.

이 분야에서 진전을 크게 이뤘던 것은 합성곱 신경망을 도입한 이후입니다. 콘브넷 (Convnet)이라고도 합니다.
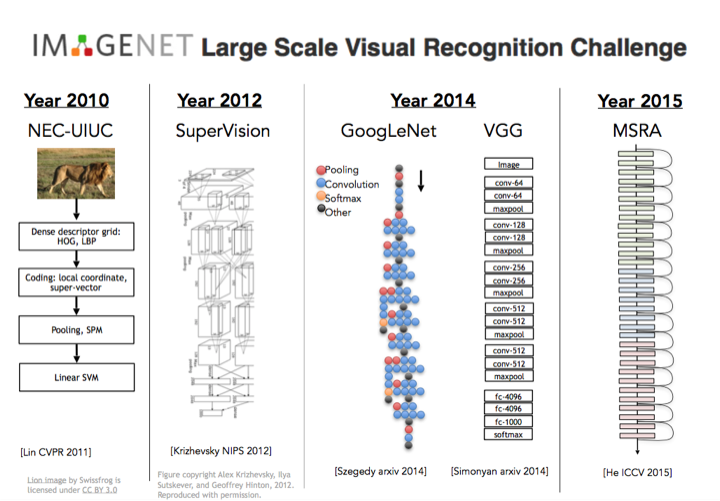
지난 몇년간 이미지넷 챌린지를 우승한 알고리즘을 보면, 2011년 린은 여전히 계층적인 방법을 씁니다. 여러 레이어를 쓰고 피쳐를 계산하고 지역 불변식 (local invariant)을 계산하고, 약간의 풀링, 그리고 여러 레이어 처리를 거쳐 결과로 나온 디스크립터를 SVM (support vector machine)에 넣습니다. 여전히 계층적이고 엣지를 찾고, 불변식 개념이 있죠. 이 직관들이 콘브넷으로 이어집니다. 돌파구는 2012년에 나왔는데 토론토의 제프 힌튼 그룹과 알렉스 크리제프스키와 그의 박사과정 학생 일리아 서츠커버가 이 7 레이어의 합성곱 신경망을 만들었습니다. 지금은 알렉스넷으로 알려져 있고 슈퍼비전이라고 불리웠습니다. 2012년 이미지넷에서 굉장히 잘했습니다.
그 이후 이미지넷 우승은 신경망 차지였습니다. 매년 점점 더 깊어졌는데, 알렉스넷은 7 혹은 8 레이어 신경망이지만, 2015년엔 더 깊어졌고, 구글넷도 그렇고, 옥스포드의 VGG는 당시 19레이어였습니다. 2015년엔 완전 미쳐서 마이크로소프트 리서치 아시아에서 나온 레지듀얼 네트웍 (Residual Network)는 152 레이어였죠.
이후 200까지 가면 더 성능이 좋았지만, GPU 메모리가 부족했습니다. 기억해야 할점은 2012년에 합성곱 신경망 등장이 돌파구 순간이였다는 겁니다. 그 이후 이미지 분류 문제에 더 잘 동작하도록 하기 위해서, 이 알고리즘을 튜닝하고 변경하기 위해 많은 노력이 있었습니다.

정말 중요한 건 2012년 이미지넷에서 이게 잘 동작했는데 2012년에 발명된건 아니라는 겁니다. 이전에 이미 오랫동안 있었는데요.

합성곱의 기초적인 작업은 90년대에 있었죠. 얀 르쿤과 그의 동료가 당시 벨 랩 (Bell Lab)에 있었는데, 1998년에 이 합성곱 신경망을 숫자 인식을 위해 만듭니다. 그들은 이걸 배포해서 손으로 쓴 수표나 우체국에서 주소를 자동으로 인식하게 하려고 했죠. 이미지의 픽셀을 받아들여서 어떤 숫자인지 어떤 글자인지 분류하려고 했으며, 이 구조는 알렉스넷과 유사합니다. 2012년의 그림을 보면 90년대의 것과 많은 것을 공유합니다.
이게 90년대부터 있었는데 왜 갑자기 최근 많이 사용하게 되었을까요? 90년대와 달리 변화한 점들이 있습니다. 하나는 컴퓨팅 능력이죠. 무어의 법칙 (Moore's law) 덕분으로 매년 더 빠른 컴퓨터가 나옵니다. 이건 대충 측정한 거지만, 칩의 트랜지스터 숫자를 90년대보다 보면 몇 자리수가 증가했는지 알수 있죠. 또한 GPU (Graphical Processing Unit)가 등장해 슈퍼 병렬처리가 가능하고, 결국 이 계산이 많이 필요한 합성곱 신경망을 빠르게 처리할 수 있게 됩니다. 더 많은 컴퓨터가 생겨서, 연구자들이 더 큰 아키텍처를 탐험해 보고, 더 큰 모델을 만들고, 어떤 경우는 단지 모델 크기만 늘려도 이 전통적인 접근 방법과 알고리즘이 잘 동작하기도 했습니다. 계산을 증가시키는 이 아이디어는 딥러닝 역사에 매우 중요합니다.
두번째 바뀐 점은 데이타입니다. 이 알고리즘들은 데이타에 배고파합니다. 많은 레이블된 이미지를 넣어야 하고 레이블된 픽셀을 넣어줘야 잘 동작하죠. 90년대엔 레이블된 데이타가 없었죠. 아마존 머케니컬 턱 (Amazon Mechanical Turk)같은 툴이 있기 전이고 인터넷이 널리 사용되기 전이죠. 다양한 데이타셋을 구하기 어려웠습니다. 2010년대에는 파스칼이나 이미지넷 같은 크고 고품질 데이타셋 즉, 90년대보다 몇자리수가 더 큰 데이타가 존재합니다. 이 큰 데이터로 우리는 더 큰 용량의 모델로 작업할 수 있고, 이 모델을 훈련하면 실세계 문제에 잘 동작합니다. 기억할 만한 중요한 점은 합성곱 신경망이 멋지고, 새롭고, 몇 년전 나온 것 같지만 그렇지 않다는 겁니다. 이 알고리즘은 오랫동안 존재했습니다.

컴퓨터 비전 분야는 사람처럼 보는 기계를 만드는 일을 하고 있습니다. 사람은 시각으로 더 많은 일을 하죠. 우리는 돌아다닐 때, 박스를 그리는 것 , 개 고앙이 구분하는 것만 하지 않습니다. 여러분의 시각은 이것보다 훨씬 강력합니다. 이 분야에는 우리가 해결해야할 엄청나게 많은 열린 문제와 챌린지들이 있습니다. 계속 알고리즘을 개발해서 더 야심찬 문제를 더 잘 해결하기 위해서 말입니다.

몇 가지 예를 들자면, 의미적 구분이나 지각적인 그룹핑 (grouping), 이미지 전체를 레이블하기보다 이미지의 모든 픽셀을 이해하고자 하는 것입니다. 픽셀이 뭘 하고 뭘 의미하는지를 말입니다. 이 3차원 이해하자는 아이디어 즉, 전세계를 재구성하는 아이디어 연구는 아직 풀리지 않았죠. 상상할 수 있는 정말 많은 다른 작업들이 있습니다.
어떤 사람의 행동을 보여주는 비디오를 받으면 그 행동을 인식하는 좋은 방법은 뭘까요? 그것도 상당히 챌린징 (challenging)한 문제입니다. AR이나 VR 영역을 보면 새로운 기술과 새로운 센서가 등장하여, 이 분야에서 풀어야 할 많은 새로운 재밌지만 어려운 문제들이 나와 있습니다.
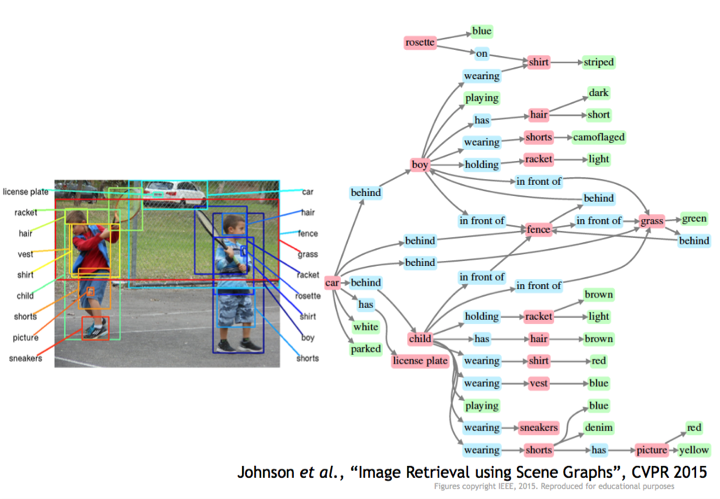
스탠포드 대학 비전 랩 (Vision Lab)의 저스틴 존슨의 개인 연구로 예를 들자면, 비주얼지놈 (visualgenome) 데이타셋으로 복잡한 사항 (intricacy)을 찾아 실 세계 이미지에서 단지 박스를 그리기 보다는 오른쪽의 이 큰 그래프로 이미지를 설명하는 것입니다. 의미적으로 연관된 개념으로 말입니다. 단지 물체 인식만이 아니라 물체 관계, 물체 속성, 장면에서 벌어지는 행동, 이런 표현이 우리가 이 비주얼 세계의 풍부함의 일부를 이해하게 합니다. 왼쪽은 단순한 이미지 분류이구요. 이게 지금 표준은 아니지만 여러분의 시각이 단순한 이미지 분류 셋업에서 찾지 못하는 것을 많이 찾을 수 있다는 것을 확인할 수 있는 예입니다.

이런 방향으로 또 재밌는 것은 페이페이 (Fei-Fei)의 대학원 시절에서 가져온 것인데, 그녀가 칼텍 (Caltech)에서 박사과정일때 지도 교수와 함께한 연구입니다. 지나가는 사람의 길을 막고 0.5초 동안 이미지를 보여주고, 이렇게 짧게 보여줬는데 사람들은 이렇게 긴 이야기를 쎴습니다. 만약 더 오래 봤다면 소설을 썼을 겁니다. 이 사람은 누구이고 왜 게임을 운동장에서 하고 있는지 등등이요. 외부 지식과 자기 경험도 가져와서 말입니다. 이것이 어떤 점에선 컴퓨터 비전의 금과옥조입니다. 이미지를 풍부하고 깊게 이해하는 것 말입니다. 지난 몇 년간의 엄청난 진보에도 불구하고 이 금과옥조를 이루기 위해서는 갈 길이 멉니다.

다른 예는 안드레 카파씨 (Andrej Karpath)의 블로그에서 가져온 건데요. 바로 이 놀라운 이미지입니다. 꽤 재밌는 이미지죠. 왜 재밌죠? 저울에 어떤 사람이 서 있는데, 사람들은 몸무게에 대해선 남을 의식합니다. 저울로 몸무게를 재는데 뒤의 다른 사람이 저울을 발로 누르고 있죠. 그럼 저울 눈금이 올라가죠. 근데 그 사람이 미국 대통령인 버락 오바마라는 겁니다. 미국 대통령은 존경받을 만한 정치인이고 자국민을 이런식으로 놀리지 않을 것 같은데요. 뒤에 보면 웃고 있는 사람들이 있습니다. 이 장면을 이해하는 한다는 거죠. 그들은 오바마를 보고 있구요. 등등 이건 미친 수준입니다. 이 이미지엔 많은 일이 벌어지고 있습니다. 우리의 컴퓨터 비전은 이런 깊은 이해를 하기엔 갈 길이 멉니다. 연구자로서, 풀어야 할 짜릿하고 멋진 문제가 많다는 사실에 흥분됩니다.

컴퓨터 비전이 재밌다는걸 여러분께 잘 확신시켜 준 것 같은데요. 컴퓨터 비전은 짜릿한 분야고 유용하며 여러가지 면에서 세상을 더 좋은 곳으로 만들 것입니다. 의료 진단이라든가 자율주행, 로봇, 이 모든 분야에서요. 게다가 인간의 지능을 이해하는 핵심 아이디어에 이르기까지요. 저에게는 환상적으로 놀랍고 재밌는 영역입니다. 우리는 깊이 파고 들어 이 알고리즘들이 어떻게 동작하는지에 대해 이 모든 세부사항에 대해서 알아볼 겁니다.

여러분은 이 알고리즘들이 어떻게 동작하는지 깊이 알아야 합니다. 이 신경망을 붙이면 어떤 일이 벌어지는지, 이 아키텍처 결정이 네트워크 학습에, 테스트에 어떻게 영향을 미치는지를요. 과제를 통해서 여러분 자신의 신경망을 밑바닥부터 파이썬으로 만들게 될겁니다. 순방향으로도 역방향으로도 만들거고 마지막엔 결국 여러분 자신의 멋진 신경망이 될 겁니다.
우리는 실용적이길 원합니다. 사람들은 요즘 이걸 밑바닥부터 만들지는 않습니다. 우리는 여러분에게 최첨단의 소프트웨어 도구를 제공할 것이고 실제로 이런 알고리즘들을 위해 상용중인 텐서플로우, 파이토치 같은 것들입니다.
이 과정은 최첨단이고 매우 흥분시키는 과정이며 매우 빠르게 변화하는 내용입니다. 2012년 이후 이미지넷의 이 플롯도 엄청난 진전이 있었고 제가 대학원에 있는 동안 매년 이 분야는 변신했습니다. 올해 다루는 내용이 작년에는 없던 것일수 있는데, 막 나온 따끈따끈한 것을 엮어서 여러분에게 제공하는 것을 제일 좋아합니다.

이미지 캡셔닝도 재밌습니다. 우리가 이미지를 설명을 하는 것이죠. 딥드림 (DeepDream)같은 신경망을 훈련시켜, 이 미친 환각을 일으키는 이미지를 만드는 것도 하고, 예술적인 것도 할 것이며, 코스 끝엔 이게 어떻게 동작하는지 알게 될 것입니다. 오른쪽의 스타일 트랜스퍼 (style transfer) 아이디어는 우리가 사진을 찍어서 피카소나 반 고흐 같은 유명화가의 스타일로 만드는 것입니다.
'AI' 카테고리의 다른 글
[cs231n] 2강 이미지 분류 (3/4, K-최근접 이웃/ K-Nearest Neighbors) (0) 2021.01.05 [cs231n] 2강 이미지 분류 (2/4, 최근접 이웃 / nearest neighbors) (0) 2021.01.04 [cs231n] 2강 이미지 분류 (1/4, 챌린지) (0) 2021.01.04 [cs231n] 1강 시각 인식을 위한 합성곱 소개 (2/3, 컴퓨터 비전 역사) (0) 2021.01.01 [cs231n] 1강 시각 인식을 위한 합성곱 소개 (1/3, 소개하기) (1) 2020.12.31