-
[cs231n] 2강 이미지 분류 (1/4, 챌린지)AI 2021. 1. 4. 17:44

지난 시간엔 컴퓨터 비전이 무엇인지와 역사에 대해 배웠죠. 그리고 이 강좌 개요에 대해서도요. 오늘은 세부 사항들을 들여다 보겠습니다. 이 알고리즘이 어떻게 동작하는지에 대해서요.
첫 강의는 비전에 대한 빅 픽쳐였고, 오늘 강의의 대부분은 세부사항들을 볼 겁니다. 여러 다른 알고리즘에 대한 세부 메커니즘을 볼 건데, 오늘 알고리즘을 처음 배우는 날이라 흥분되네요.

우리는 파이썬 넘파이 튜토리얼을 써서 올렸습니다. 코스 웹사이트에요.넘파이는 효율적인 벡터화된 연산을 가능하게 해서 상당한 연산을 코드 몇줄로 하게 해줍니다. Numerical 컴퓨팅이나 머신러닝같은 것들은, 이 벡터화된 오퍼레이션으로 효율적으로 구현됩니다.
- NumpyTutorial: cs231n.github.io/python-numpy-tutorial/
Python Numpy Tutorial (with Jupyter and Colab)
This tutorial was originally contributed by Justin Johnson. We will use the Python programming language for all assignments in this course. Python is a great general-purpose programming language on its own, but with the help of a few popular libraries (num
cs231n.github.io

구글 클라우드는 아마존 AWS와 비슷한 건데, 가상 머신을 클라우드에서 시작할 수 있습니다. 가상 머신은 GPU가 있습니다. 구글 클라우드 튜토리얼도 썼습니다.
- Google Cloud Tutorial: github.com/cs231n/gcloud
cs231n/gcloud
Google Cloud tutorial and setup. Contribute to cs231n/gcloud development by creating an account on GitHub.
github.com

지난 강의에서 이미지 분류에 대해서 봤는데요. 컴퓨터 비전의 핵심 작업이죠. 이 강좌 전체에 걸쳐서 집중하는 내용이죠. 즉, '어떻게 이미지 분류 작업을 할까?'입니다. 좀 더 구체적으로, 이미지를 분류할 때, 여러분의 시스템은 이 고양이 같은 이미지를 입력으로 받고, 시스템은 어떤 미리 정해진 카테고리나 레이블을 알고 있습니다. 이미지들은, 개, 고양이, 트럭, 비행기 같은 것일 수도 있고 정해진 카테고리 레이블 집합이 있고, 컴퓨터가 하는 일은 그림을 보고 정해진 카테고리 레이블로 지정하는 겁니다.
쉬운 것같아 보이죠. 사람의 뇌속의 시각 체계는 이런 일을 하는 재능을 타고 났죠. 즉, 시각적인 인식을 의미합니다.
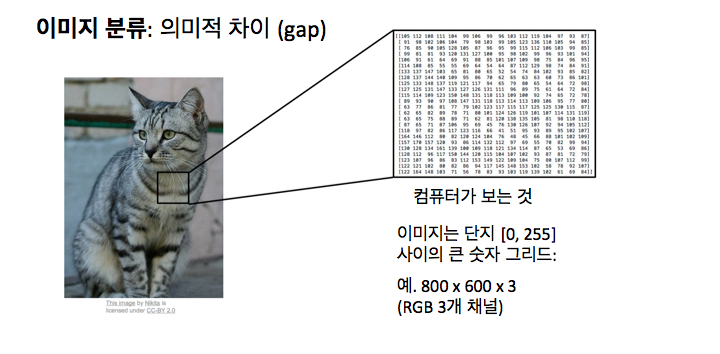
기계에겐 매우 어렵습니다. 파고 들어서 생각해 보면, 컴퓨터가 이 이미지를 볼 때 실제 보는 것으로는 여러분이 볼 때의 전체적인 고양이의 아이디어를 얻지 못합니다. 컴퓨터는 실제로 엄청난 숫자 그리드로 이미지를 표현합니다. 이 이미지는 800 x 600 픽셀인데, 각 픽셀은 3가지 숫자로 표현됩니다. 픽셀에 대한 빨강, 초록, 파랑 값을 주는 거죠. 컴퓨터에게는 큰 그리드 숫자일 뿐이고, 거기서 고양이 성질을 끌어내기 어렵죠. 이 문제를 의미적 차이 (semantic gap)라고 합니다. 고양이라는 생각, 혹은 고양이 라벨은 우리가 부여한 의미적 레이블이죠.
고양이라는 의미적 아이디어와 컴퓨터가 보는 이 픽셀 값 사이엔 엄청난 차이이 존재하죠.
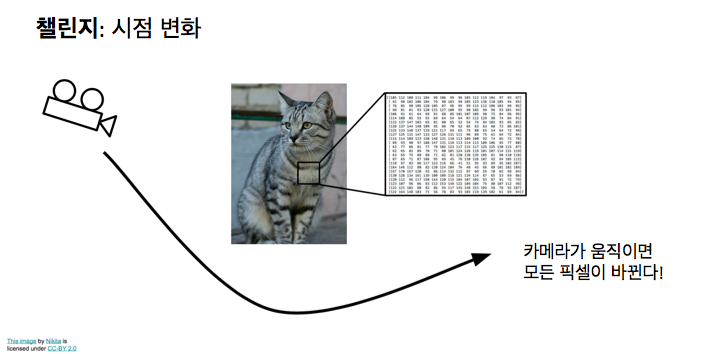
정말 어려운 문젠데 여러분은 그림을, 매우 작은 미묘한 방법으로도 바꿀 수 있고, 그에 따라 픽셀은 전체적으로 다 바뀝니다. 예를 들면, 같은 고양이를 찍어도 고양이가 가만히 앉아 있기만 한다던지, 씰룩거리지 않거나 근육하나 움직이지 않고 있을 리가 없습니다. 카메라를 다른 방향으로 움직이면, 이 엄청난 그리드에서 모든 픽셀 값이 완전히 달라집니다. 그러나 같은 고양이를 나타내고 있는 것입니다. 우리 알고리즘은 이런 변화에도 견고해야 합니다.

어디서 찍었느냐는 문제 말고, 또 다른 건 조명이죠. 장면 마다 다른 조명 조건이 있을 겁니다. 고양이가 이런 어두운 곳에 보이든지, 이런 밝은 햇빛 아래 있든지, 우리 알고리즘은 동작해야 합니다.

물체가 형태를 바꿀 수도 있죠. 고양이는 아마 모양을 가장 잘 바꿀 수 있는 동물일거 같네요. 고양이는 다양한 포즈를 취할 수 있죠. 이런 변형에도 알고리즘은 동작해야 합니다.

가리는 문제도 있죠. 고양이를 일부만 보게 됩니다. 얼굴만 보거나, 소파 쿠션 사이로 꼬리만 보이는 경우도 있죠. 사람에겐 아마 고양이일거라는 것을 알아차리는 것은 매우 쉽죠. 우리의 알고리즘은 이런 조건에도 견고해야 합니다. 매우 어려운 일입니다.

배경이 어수선한 문제도 있죠. 앞에 있는 것은 고양이인데, 뒤 배경과 매우 유사한 경우입니다. 이런 경우도 처리해야 합니다.

이건 클래스내 변화 (intraclass variation)인데요. 고양이 다움이 여러 다양한 시각적 모습에 걸쳐 나타납니다. 고양이는 다양한 모양과 크기와 색깔과 나이로 나타나죠. 우리 알고리즘은 이런 모든 변화에 대응할 수 있어야 합니다.
매우 챌린징한 문제죠. 인간에게는 이런 문제가 쉽죠. 인간의 뇌는 이런 것을 다루는데 튜닝이 잘 되어 있으니까요. 그러나 컴퓨터 프로그램이 이 모든 문제를 다루게 하고 싶다면 어떨까요? 모두 동시에요. 거기다 고양이만의 문제가 아닙니다. 상상할 수 있는 모든 물체에 대해서죠. 환상적으로 챌린징한 문제이고, 이게 동작한다는게 기적과도 같은 일 같습니다. 근데 이게 동작할 뿐 아니라, 어떤 제한된 조건에서는, 사람과 비슷한 정도의 정확도로 동작합니다. 수백 밀리세컨드 (milisecond) 만에요. 정말 놀랍고 믿을 수 없는 기술이죠.
'AI' 카테고리의 다른 글
[cs231n] 2강 이미지 분류 (3/4, K-최근접 이웃/ K-Nearest Neighbors) (0) 2021.01.05 [cs231n] 2강 이미지 분류 (2/4, 최근접 이웃 / nearest neighbors) (0) 2021.01.04 [cs231n] 1강 시각 인식을 위한 합성곱 소개 (3/3, 강좌개요) (1) 2021.01.01 [cs231n] 1강 시각 인식을 위한 합성곱 소개 (2/3, 컴퓨터 비전 역사) (0) 2021.01.01 [cs231n] 1강 시각 인식을 위한 합성곱 소개 (1/3, 소개하기) (1) 2020.12.31