-
[cs231n] 2강 이미지 분류 (2/4, 최근접 이웃 / nearest neighbors)AI 2021. 1. 4. 19:55

이미지 분류를 위한 API가 뭔지 생각해 보면, 파이썬으로 이런 메소드를 아마 작성할 겁니다. 이미지를 받아서 어떤 미친 마법을 부려서 고양이인지 개인지 아무것도 아닌지 레이블을 뱉어내는 거죠. 어떤 명확한 방법은 없습니다. 알고리즘 수업을 듣고 있는 거라면, 정렬하고, 컨벡스 헐 (Convex Hull) 계산하거나 RSA 암호화하거나 하는, 어떤 알고리즘을 작성할 수 있을 겁니다. 이걸 하기 위해서, 일어나야 하는 여러 단계를 나열하죠. 물체를 인식하기 위해서, 혹은 고양이나 이미지를 인식하기 위해서는 명확한 명시적 알고리즘이 없습니다. 이런 직관적인 감각을 만드는 혹은 어떻게 이런 객체를 인식할지에 대한 알고리즘은 없죠.
이게 챌린징한데, 만약 처음 프로그램밍하는 날, 이런 펑션을 써야 한다면 대부분의 사람은 곤란해 할 겁니다. 그 말은 사람들이 지금까지 명시적 시도를 해왔다는 것입니다. 여러 동물을 인식하기 위해서, 일종의 하이엔드 코딩된 룰을 작성하려고 했죠.
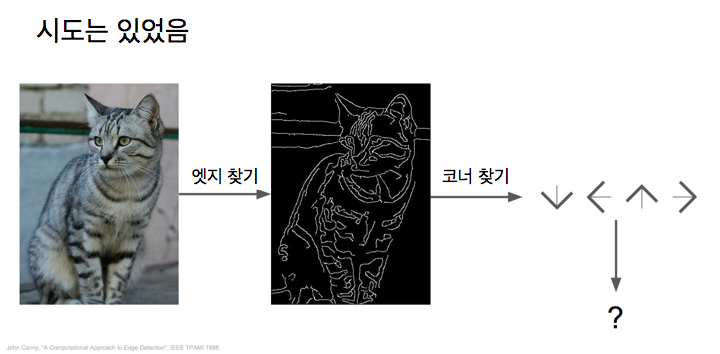
고양이에 대한 아이디어를 보면, 우리는 고양이가 눈, 귀, 코, 입이 있다는 걸 알고, 그 엣지들을 알고, 휴벨과 위젤이 그랬듯이요. 비주얼 인식에 있어서는 엣지가 중요합니다. 우리가 해 볼 수 있는 것은, 이미지의 엣지를 계산해서 다양한 코너와 경계를 분류하는 거죠. 이 세 라인이 만난다면 이게 코너고, 귀는 여기에 한 개 코너, 저기에 코너 한 개, 이런 식으로 명시적 룰의 집합으로 고양이를 인식하는겁니다.
그러나 이게 잘 동작하지 않는 걸로 판명났습니다.
첫째 매우 불안정하구요.. 다른 카테고리에서 시작하면, 고양이는 이제 생각하지말고, 트럭, 물고기, 개 등 다른거요. 이걸 처음부터 다시 해야 합니다. 이건 확장가능한 (scalable) 방법이 아닙니다. 우리는 이 인식 작업을 훨씬 더 자연스럽게 확장할 수 있는, 어떤 알고리즘, 메소드을 생각해내서 세상의 모든 물체를 인식하고 싶은거죠.

이 모든 것은 동작하게 할 인사이트는 데이타 추진 (data-driven) 접근 방법 아이디어에 있습니다. 뭐가 고양이인지 물고기인지 알아내기 위해 앉아서 손으로 지정하는 룰을 작성하기 보다는 우리는 인터넷으로 가서 큰 데이타 셋을 모읍니다. 수많은 고양이, 수많은 비행기, 수많은 사슴, 등등 구글 이미지 서치 같은 도구를 사용하여 이 다양한 카테고리에 대한 매우 많은 이미지를 모읍니다.
이건 꽤 많은 노력을 요구하는데, 여러분이 사용할 수 있는 고품질 데이타 셋은 이미 있습니다. 이 데이타 셋을 가지면, 우리는 머신러닝 분류기를 훈련시킵니다. 이 모든 데이타를 삼켜서, 어떤 식으로 요약을 한 후, 모델을 뱉어내죠, 어떻게 이 다양한 물체 카테고리를 인식할지에 관한 지식을 요약한 것을 말입니다.
우리는 결국 이 학습 모델을 사용해서 새로운 이미지에 적용해 봅니다. 개인지 고양인지 아닌지 인식할수 있도록 말이죠. 여기서 우리의 API가 좀 바뀌었습니다. 이미지를 받아서 고양이인지 인식하는 하나의 함수가 아니라, 두개의 함수가 있죠. 하나는 학습이라서 이미지와 레이블을 입력받아 모델을 출력하고, 다른 하나는 예측이죠. 모델을 받아서, 이미지에 대해 예측하는 겁니다. 이것이 주요 인사이트입니다. 지난 10, 20년동안 이 모든 것이 동작하게 만들었죠.
이 강좌는 주로 신경망과, 합성곱 신경망, 딥러닝, 에 관한 강좌인데, 이 데이타-추진 접근 방법 아이디어는 딥러닝 보다 훨씬 더 일반적입니다. 큰 복잡한 것을 보기 전에, 먼저 이런 단순한 분류기에 대한 단계를 거쳐보는 것이 유용해 보입니다.
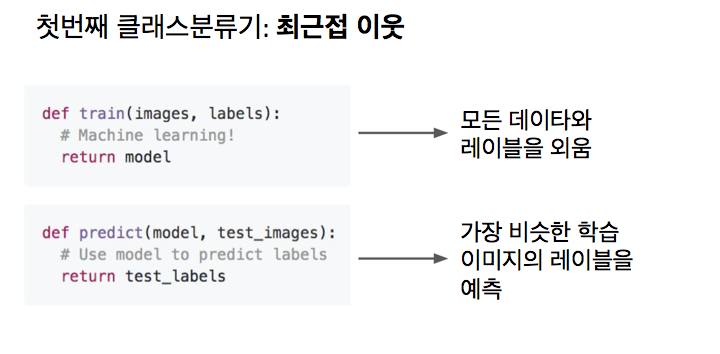
아마 여러분이 생각할 수 있는 가장 단순한 분류기는 우리가 최근접 이웃 (nearest neighbors)이라고 부르는 것일 것입니다. 이 알고리즘은 꽤 멍청합니다. 솔직히 말하면요. 훈련 단계에서는, 아무것도 안하고, 학습 데이타를 그냥 암기합니다. 간단하죠. 예측 단계에서, 새 이미지를 받아서 학습 데이타 중에서 그것과 가장 비슷한 것을 찾아 그 이미지의 레이블로 예측합니다. 매우 간단하죠. 그러나 데이타-추진 방식이라는 좋은 속성을 가지고 있네요.

더 구체적으로, CIFAR 10이라는 데이타 셋으로 작업하는 것을 생각해 볼 수 있는데, 작은 테스트 케이스로 머신러닝에서 흔하게 사용되는 데이타 셋이죠. CIFAR 10 데이타셋은 10개의 클래스를 제공하는데, 자동차, 비행기, 새, 고양이 등등이 있습니다. 10개 카테고리의 5만 학습 이미지를 제공하고 10개 카테고리에 골고루 분포되어 있으며, 여러분의 알고리즘을 테스트할 수 있는 1만개의 테스트 이미지가 있습니다.

CIFAR 10의 테스트 이미지에 최근접 이웃을 적용한 예인데요. 오른쪽 그리드에서 제일 왼쪽 열이 시파10 테스트 이미지이고, 오른쪽은 학습 이미지를 정렬해서 가장 비슷한 이미지를 보여줍니다. 시각적으로는 학습 이미자와 비슷하다고 볼 수 있죠. 비록 항상 맞는건 아니지만요. 두번째 열을 보면, 이미지가 32 x 32 크기라서 보기 어려운데, 잘 보고 추측해야 합니다.
두번째 행을 보면 이 이미지는 개인데, 최근접 이웃도 개이네요. 그 다음것을 보면 사슴 혹은 말이 있죠. 시각적으로는 비슷해 보인다는 것을 알 수 있습니다. 하얀 부분이 가운데 있고요. 최근접 이웃 알고리즘을 적용하면, 학습 데이타의 가장 비슷한 예를 찾을 수 있습니다. 가장 가까운 예의 레이블을 학습 셋에서 확인할 수 있고, 그럼 테스트 이미지가 개라고 얘기하는 겁니다.
이 예를 보면 이게 아마도 잘 동작하지 않을 거라는 것을 알 수 있을 겁니다. 그러나 여전히 훑어볼 좋은 예입니다. 알고 있어야 할 세부사항이 있는데, 한쌍의 이미지가 주어지면 그걸 어떻게 비교할 수 있을까요?
우리가 테스트 이미지를 받으면 모든 학습 이미지와 비교해야 하는데 말이죠. 그 비교 함수가 어떻게 생겨야 하는지에 대해서는 사실 많은 옵션이 있습니다.

지난 슬라이드에서 L1 거리를 사용했습니다. 맨하탄 거리라고도 하는데, 이미지 비교하는데 간단하고 쉬운 아이디어입니다. 이미지내의 각각의 픽셀을 비교하는 겁니다. 만약 우리 이미지가 4 x 4의 작은 이미지면 픽셀값은 테스트 이미지의 왼쪽 위 픽셀 값에서 학습 이미지의 왼쪽 위 값을 뺍니다. 그리고 절대값을 취하면, 두 이미지의 차이가 구해지고, 모든 차이를 더하는 겁니다. 이미지를 비교하는 이건 바보같은 방법인데, 가끔 구체적인 두 이미지 비교 방법을 제공하는 합리적 방법으로 보이기도 합니다. 이 경우 456 차이가 나네요.

여기 최근접 이웃 분류기의 전체 파이썬 코드가 있습니다. 넘파이가 제공하는 벡터화된 연산을 써서, 꽤 짧고 간결하죠.

여기서 우리는 앞서 얘기한 학습 함수를 볼 수 있는데, 최근접 이웃의 경우엔 매우 간단합니다. 학습데이타를 외우기만 해서 할 것이 별로 없습니다.

테스트 시에는, 테스트 이미지를 받아서 이 학습 예들과 L1 거리 함수를 이용해 비교합니다. 그래서 학습 데이타 셋에서 가장 비슷한 예를 찾는거죠. 파이썬 코드 1,2줄로 넘파이의 벡터화된 연산을 써서 가능합니다.

이 간단한 분류기에 대해 몇 가지 질문을 해 보겠습니다. N개의 학습 데이타가 있을 때, 훈련과 테스트가 얼마나 빠를가요?

학습은 상수이죠. 데이타만 학습하면 되니까요. (Big O notation, O(1)) 포인터만 복사하면 됩니다. 데이타가 얼마나 크던지 상관없죠. 하지만 테스트 시에는 이 비교 단계에서 데이타 셋의 N개의 예에 대해 테스트 이미지와 비교해야 합니다. 이건 꽤 느립니다.

이건 약간 우리가 원하는 것과 거꾸로 인데, 생각해 보면, 실제로 우리는 분류기가 학습시에는 느리고, 테스트 시에는 빠르길 바랍니다. 상상하듯이, 어떤 데이타 센터에서 학습이 될 거고, 여러분은 많은 계산을 할 수 있는 여유가 있을 겁니다. 그럼 학습 시에 좋은 분류기를 만들 수 있겠죠. 테스트 시에 분류기를 배포하게 되면, 이걸 모바일 폰이나 브라우저나 저전력 기기에서 실행하려고 할텐데, 테스트 시의 분류기가 꽤 빠르길 바랄 것입니다. 이런 관점에서 보면, 이 최근접 알고리즘은, 사실 거꾸로 된 것이죠.
일단 합성곱 신경망이나 다른 파라미터 모델로 넘어가면 이것과 반대가 됩니다. 그땐, 학습에 많은 시간을 쓰고, 테스트는 빨라지죠.

다른 질문을 하자면, 이 최근접 알고리즘은 어떻게 생겼죠? 실제 문제에 적용할 때 말입니다. 최근접 이웃 분류기의 결정 영역 (decision region)이라는 걸 여기 그려봤는데, 우리의 학습 셋은 이차원 평면위의 이 점들로 이뤄져 있습니다. 점의 색은 카테고리를 나타내는데, 그 점의 클래스 레이블이라고 할 수 있죠. 여기 5개 클래스가 있고, 파란색은 위쪽 구석에, 보라색은 위쪽 오른쪽 구석에 있네요. 이 전체 평면의 각 지점에 대해서, 이 학습셋 중에서 가장 가까운 점은 무엇인가를 우리는 계산했습니다. 그 다음 그 가장 가까운 점의 클래스 레이블로 색칠한 겁니다. 그랬더니 이 최근접 이웃 분류기가 이 공간을 조각하는 것처럼 보이네요. 가장 가까운 점에 따라 색칠한 겁니다.
그러나 이 클래서 파이어는 그리 대단하지는 않은데, 이 그림을 보면 몇 가지 문제가 보입니다. 이 가운데 영역은 대부분 녹색인데, 가운데 노란점이 하나 있죠. 최근접 이웃만 보기 때문에, 녹색 클러스터 가운데 노란 섬이 하나 생깁니다. 별로 좋은게 아니죠. 아마 저 노란 영역은 녹색이 되어야 할 겁니다. 길게 튀어나온 것을 보게 되는데, 녹색 영역이 파란색 영역으로 밀고 들어간 것을 보면, 하나의 점이 거기 있어서죠. 아마도 노이즈이거나 비 논리적인 데이타입니다.
'AI' 카테고리의 다른 글
[cs231n] 2강 이미지 분류 (4/4, 선형 분류기) (0) 2021.01.06 [cs231n] 2강 이미지 분류 (3/4, K-최근접 이웃/ K-Nearest Neighbors) (0) 2021.01.05 [cs231n] 2강 이미지 분류 (1/4, 챌린지) (0) 2021.01.04 [cs231n] 1강 시각 인식을 위한 합성곱 소개 (3/3, 강좌개요) (1) 2021.01.01 [cs231n] 1강 시각 인식을 위한 합성곱 소개 (2/3, 컴퓨터 비전 역사) (0) 2021.01.01